平时没有用到过这个方法, 第一次接触到这个方法的时候, 是在知乎上的一个问答, 以及日后也有了解到一些面试官会考这个, 但是看到网上的解答, 都不是太容易理解, 本来一个很简单的概念, 让他们整的神乎其神. 这里来记录一下我的理解.
首先要理解这个概念, 我们必须清楚几个概念.
- String作为一种引用类型, 如果你要通过new关键字来创建一个String类型, 那么这个类型肯定是会在堆中生成的.针对其他引用类型这个也是一样的.
- java7及以上的版本将
字符串常量池移动到了堆中. (什么, 你不知道字符串常量池? 甚至不知道堆? 那这不是本篇文章要涉及的内容) intern()方法是一个JNI方法, 它的功能是返回在字符串常量池中存在的'引用'.equals(s),s为调用intern()的实例.- 对于代码中出现的字符串常量, 当运行该方法的时候, 会自动先在字符串常量池中生成一个该字符串的对象.
- 使用
String str = "some str", 生成的String实例, 会先字符串常量池中, 查找到直接返回其引用, 如果查找不到, 那么就在常量池中直接创建, 然后返回引用.
其实你只要知道以上的几个概念, 你就应该可以理解面试中出现的代码中生成了String实例, 以及他们之间的==问题.
好了, 有了上面这几个概念之后, 我们开始去证明且理解它.
先看一下下面的代码
//创建了两个String实例, 先创建一个在堆中的字符串常量池, 另一个由s1字段指向也在堆中
String s1 = new String("hello");
//s1.intern()返回字符串常量池中引用.equals(s1)的字符串引用.
s1.intern();
//s2 = "hello". 搜索字符串常量池, 如果常量池存在与引用.equals("hello"), 那么s2等于该引用
String s2 = "hello";
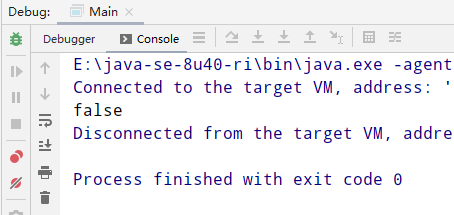
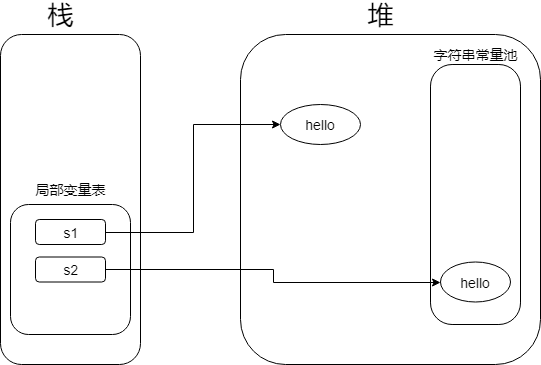
//到这里, 很显然, s1指向的还是堆中的实例, s2指向的是由字符串常量中维护的"hello"实例, 所以这两个实例不是一个实例.
System.out.println(s1 == s2);
看下运行结果
关于上面的内存结构, 我也画了一张图.
理解地比较透彻地小伙伴这时候可能就有想法了.
如果想让他返回true的话. 只需要改为s1 = s1.intern()就行了.
String s1 = new String("hello");
s1 = s1.intern();
String s2 = "hello";
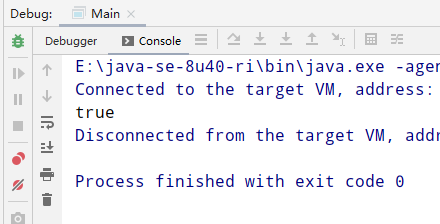
System.out.println(s1 == s2);
运行结果截图
这里通过将s1的引用定位到常量池中的hello来完成
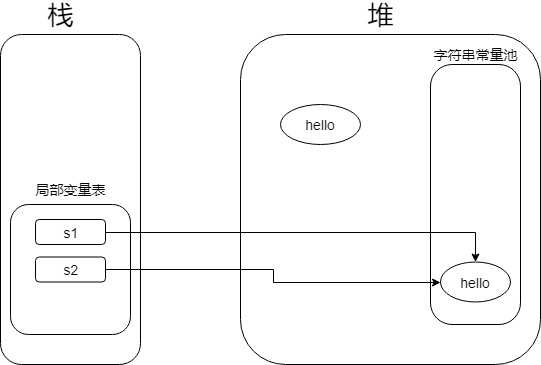
好了, 分析完上面的之后, 相信大家对于intern()已经有了不错的理解. 这里我们再变形一下.
String s3 = new String("wo") + new String("rld");
String s4 = "world";
s3.intern();
System.out.println(s3 == s4);
下面的代码, s3是通过拼接来生成的. 等到解析到下一行的时候, 会将”world”再放入常量池.
运行一下. 结果显然会是false;
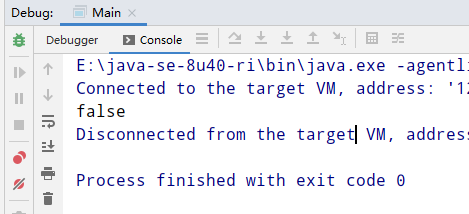
这个时候的内存中的存储情况我也大概地画了出来.
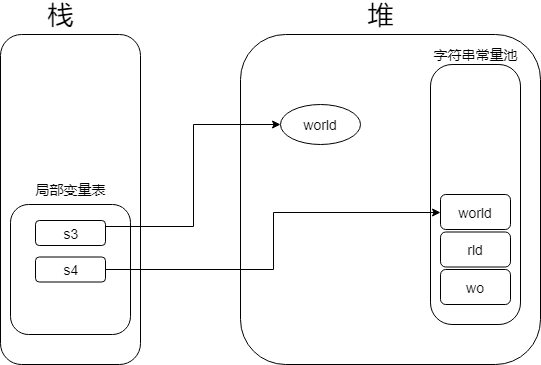
这个时候. 我们就想, 复用”world”, 堆当中有一个”world”就行了. 我们可以在合适的时候使用intern()来确保s3 和 s4的共用.
String s3 = new String("wo") + new String("rld");
//在生成s4之前, 将s3放入字符串常量池, 确保s4生成的时候进行复用.
s3.intern();
String s4 = "world";
System.out.println(s3 == s4);
看下结果.
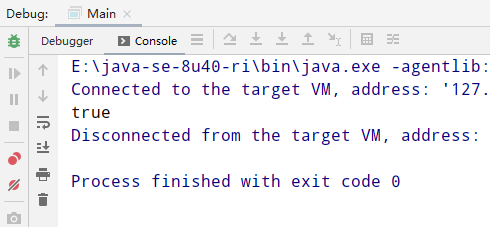
内存情况
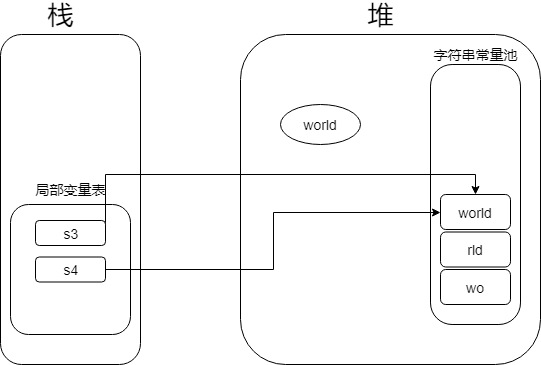
基本上通过上面的例子, 对于String的intern()方法已经可以理解了.
其实堆中的字符串常量池, 在jdk7之前是放在方法区中的, 但是在jdk7的时候调整到了堆当中.
不过实现结构都是JNI调用c++实现的StringTable的intern方法, StringTable的实现和HashMap差不多, 但是不能自动扩容. 默认的大小是1009, 所以, 当存入的常量池中的字符串过多的时候, 一定要通过jvm的启动参数来增大StringTable的大小, 不然, 就会造成table中的链表过长, 从而效率严重降低.
-XX:StringTableSize=99991
参考资料:
深入解析String#intern